La capacité de savoir où et comment chercher, trouver et identifier les informations pertinentes, de faire le tri, de sélectionner, de relier et d'attribuer les bonnes valeurs aux informations selon le contexte devient une habileté essentielle.
L'enquêteur apprend à poser les bonnes questions. Comment fait-on pour poser de bonnes questions ? On sait ce que l'on veut atteindre, on s’informe et on organise l'information. Quoi d'autre ?
Et si l’excellence de la recherche passait aussi par les bons outils ?
Aujourd’hui nous vivons dans une jungle d’information et dans l’ère du Fake dans tous les domaines de notre vie, avec certaines informations pertinentes, certaines inutiles et encore d’autres fausses. L’utilisation des moteurs de recherche actuels ne permet pas de faire le tri au premier abord entre toutes ces données non catégorisées. Ces même moteurs de recherche cherchent par l’orthographe des mots ou quelques fois aussi par les orthographes approchées, mais que fait-on avec les sens multiples ? Que fait-on des contextes ?
Prenons un exemple simple, le mot «canard». Selon les cas de figure, c’est un animal ou un journal ou une fausse note ou un sucre trempé dans le café ou une figure de surf ou une technique de plongée ou une nouvelle dont la source est peu fiable.
Si on cherche le mot canard sur Google, on obtient autour de 28 000 résultats et vient en premier sur la première page la définition wikipédia (https://fr.wikipedia.org/wiki/Canard), des recettes de cuisine, une vidéo sur les animaux de la ferme, une autre sur le conte du “Vilain petit canard”, le wikitionnaire,...
Si je connais les liens entre les choses, je peux adjoindre un deuxième mot pour contextualiser ma recherche. Par exemple, en cherchant avec les mots conte et canard, j’obtiens 80% de “Vilain petit Canard” et 20% de découvertes autres. Cet exemple nous montre deux choses. La première est que si vous ne connaissez pas l’objet et sa localisation dans le champs des savoirs, vous ne pouvez pas trouver les sujets contextuels. La seconde est que les champs des réponses possibles sont définis et fermés par la capacité technologique des outils de recherche.
Quels impacts sur les champs possibles de nos recherches ?
Il est connu que les outils formatent la pensée.
“L'idée que la matérialité de l'écrit puisse déterminer les modalités de notre pensée ou, plus exactement, qu'il y ait réciprocité des influences des quatre composants de l'écriture les uns sur les autres n'est pas neuve [Jacob, 1996]...”.
“Le phénomène n'est pas nouveau: l'histoire de l'écriture repose sur de telles simplifications (l'adoption des chiffres indo-arabes, la réapparition de l'espace entre les mots au VIIe siècle, la normalisation des alphabets occidentaux) qui augmentent nos capacités intellectuelles et engendrent des méthodes qui déplacent les apprentissages (l'apparition de l'index au Xe siècle, l'algèbre de Descartes, etc.).
Cette double dynamique explique notre fascination et notre malaise face aux moteurs de recherche: une transformation a priori secondaire (coder du texte sous forme binaire) transforme la notion de mot, donc notre rapport au texte et à nos pratiques documentaires, et par suite, l'organisation des savoirs”.
L'internet et l'écriture de Eric Guichard, décembre 2009 sur Equipes Réseaux, Savoir & territoires ENS. http://barthes.ens.fr/articles/Guichard-internet-et-ecriture.html
Où est le champ de la créativité, des liens poétiques, philosophiques, artistiques… dans ces moteurs de recherche ? C’est un monde créé par des techniciens qui nous plonge dans la recherche factuelle triangulée. C’est un monde qui aujourd’hui trouve ses limites et qui se focalise sur l’information qu’elle soit riche, vraie, utile, sensible n’a pas d’importance, puisque les moteurs de recherche les mettent toutes sur le même pied d’égalité.
Ce sont des données consolidées par leur référencement informatique à partir desquelles des mondes sont brodés, voir même qui justifie la création de bulles spéculatives de vraies ou fausses nouvelles qui ont de réels impacts sur nos vies. Un événement ou une personne peuvent être montés en tête d’épingle ou au pilori simplement parce que la communauté qui les suit y croit ou s’en sert comme projection de leur amour ou défouloir de leur haine. C’est un monde sans nuance et sans âme.
Les limites du référencement sur internet
Pour avoir une vision globale du champ des possibles en matière de recherche d’information. Il faut aussi regarder comment est classée, référencée et indexée cette information.
“Des pages Web répertoriées dans les index géants des moteurs de recherche
On sait qu'une requête par mot ou phrase clé adressée à un moteur comme Google renvoie comme résultat l'ensemble des pages dont le texte contient cette clé. Pour ce faire, le moteur consulte non pas le Web lui-même mais un index enregistré dans sa base de données, qu'il met à jour régulièrement.
Cet index, il l'a construit préalablement en envoyant sur le réseau des algorithmes, dits bots ou crawlers, qui suivent toutes les ramifications des liens hypertexte (HTTP) à partir d'un site de départ, telle une personne qui s'amuserait à cliquer successivement sur tous les liens HTTP des pages qu'il rencontre en notant quelques mots importants de chaque page”.
«Il y aurait 4,65 Milliards de pages web ... au bas mot»
par Roman Iknicoff - https://www.science-et-vie.com/
Donc, si le mot que vous recherchez n’existe pas ou peu dans les index, alors vous ne trouverez pas l’information. Cette situation peut générer un lissage de l’information au profit de la standardisation de masse plutôt que celui de la pertinence du résultat de la recherche. En fait, n’importe qui peut mettre des mots clefs, ni leur intérêt, ni leur pertinence, ni leur crédibilité ne sont régulés sinon que par le nombre de liens et de références qui y mènent.
Une nouvelle posture vient compléter ces techniques de référencement depuis peu. C’est le référencement par les pairs. C’est une nouvelle strate qui se construit. Un utilisateur, un consommateur donne son avis sur un service, un produit, une information, une personnalité et c’est la masse d’information qui fera foi. L’exemple le plus parlant est celui de www.amazon.com qui demande à ses acheteurs d’évaluer ses vendeurs. C’est intéressant, cela affine les algorithmes des Big Datas, mais, cela ne garantit en rien l’éventail du champ de la recherche, ni sa réelle pertinence.
Aujourd’hui les utilisateurs saturent, le monde des savoirs se renouvelle.
Là, où hier les âmes sensibles et leurs savoirs fuyaient Internet, on commence à les voir s’approprier elles aussi le web. Elles se créent leurs propres environnements avec leurs propres codes sociaux, sorte de règlements sensibles propres à leurs communautés. Que se passe-t-il ? Il y a saturation d’un système qui arrivent à ses limites. C’est un phénomène déjà observé par le passé :
“La relation technique-culture (dans les sociétés écrites) peut aussi être soulignée par un paramètre assez rarement mis en correspondance avec la culture: l'accroissement quantitatif de l'outillage mental du fait de la technique. La brutale multiplication des textes écrits depuis l'internet rappelle celle des revues à la fin du XIXe siècle et celle des livres dans les bibliothèques du temps de Gabriel Naudé [ Damien, 1995 ] -pour ne pas citer la bibliothèque d'Alexandrie du temps d'Ératosthène.
À chaque période le nombre de textes d'un type donnée semble être multiplié par 20. Une brutale augmentation du nombre de choses écrites produit un amoncellement étouffant et invite donc à reconsidérer les catégories qui présidaient à l'ordre antérieur des savoirs. Aucun classement documentaire ni mental ne semble résister à un tel changement d'ordre de grandeur”.
Internet et écriture - 2009 sur Equipes Réseaux,
Savoir & territoires ENS.
Il y a eu également un phénomène de décomposition des données du Big Data qui a aussi ses limites. Celles-ci sont difficilement exploitables par le fait d’un classement par segments et non par contexte.
Le découpage de l’information par segments en a fait une énorme soupe où les contextes et les liens doivent être recréés artificiellement par itération pour obtenir des algorithmes fiables, mais artificiels. On avait perdu au passage tous les liens contextuels naturels. L’arrivée des Big Data a soulevé un deuxième point essentiel, celui de la fiabilité de la donnée. Dans notre monde de Fake, une donnée aussi petite soit-elle peut elle aussi être dénaturée ou fausse, car il n’y a pas de régulation de son origine, ni de son contenu. C’est là qu’est apparu une nouvelle technologie qui répond à ce souci, celle du blockchain. Celle-ci génère des micro-informations chaînées non altérables et donc vérifiables quant à leur historique.
Quel genre de technologies et d’outils pour demain ?
Aujourd’hui, ils sont dans les labos ou les groupes de réflexion (Think Tank). Deux technologies sont à développer.
La première celle de la certification de l’information. Ceci afin d’éviter de naviguer à vue dans l’océan des données d’origines et de crédibilités diverses. La deuxième est l’extension du champ de recherche à des métas contextes qui peuvent reconstituer les liens entre des sujets connexes.
Deux projets en développement sont des pistes pour demain.
Le premier a pour objectif de certifier l’information sur Internet. Comment ? En certifiant les sources d’information. Si déjà, le tri peut être fait entre les divers émetteurs d’information, alors, ce ne sera plus l’information que l’on vérifiera, mais son émetteur. Qui est-il ? Est-il fiable ? L’exemple des diplômes est assez parlant : l’établissement qui délivre les diplômes d’une formation est l’émetteur naturel de la validation du diplôme. À qui feriez-vous confiance ? A l’université qui délivre le diplôme ou à l’étudiant qui a eu le diplôme, voire encore à un organisme de certification ?
Le meilleur certifiant est l’émetteur de l’information. Un étudiant vient d’avoir son MASTER, son diplôme est posé sur la blockchain par son université et c’est incontestable. Si l'étudiant détient des diplômes qui ne sont pas sur la blockchain, il peut les faire déposer par un organisme de certification comme un notaire, qui les posera pour lui sur la blockchain, et troisième cas, si c’est lui l’émetteur alors il sera beaucoup moins crédible que l’université et le notaire. On peut aussi certifier une information par les pairs, qui eux vont valider l’intérêt de cette information. Dans ce cas, c’est aux pairs à être certifiés en tant qu’émetteurs d’information et plus avant, on peut imaginer certifier leurs compétences, leurs savoirs, leurs aptitudes à valider une information.
 Le deuxième projet se trouve au Canada. Il a été imaginé par Pierre Levy, philosophe et professeur à Ottawa. C’est un moteur de recherche basé sur l’IEML, une sphère sémantique qui est en cours de développement et financé par le Programme des Chaires de Recherche du Canada. Une sphère sémantique est un univers autour d’un mot. Le mot n’existe pas en tant que tel, mais dans un ou de multiples univers connexes. On est dans le monde de la méta-donnée et de l’intelligence artificielle.
Le deuxième projet se trouve au Canada. Il a été imaginé par Pierre Levy, philosophe et professeur à Ottawa. C’est un moteur de recherche basé sur l’IEML, une sphère sémantique qui est en cours de développement et financé par le Programme des Chaires de Recherche du Canada. Une sphère sémantique est un univers autour d’un mot. Le mot n’existe pas en tant que tel, mais dans un ou de multiples univers connexes. On est dans le monde de la méta-donnée et de l’intelligence artificielle.
“L'information veut être ouverte, transparente et commune
Nous avons besoin d'un nouveau type de sphère publique: une plate-forme dans le nuage où les données et les métadonnées seraient notre bien commun, dédiées à l'enregistrement et à l'exploitation collaborative de la mémoire au service de notre intelligence collective. Les valeurs fondamentales qui orientent la construction de cette nouvelle sphère publique devraient être: l'ouverture, la transparence et la communauté”.
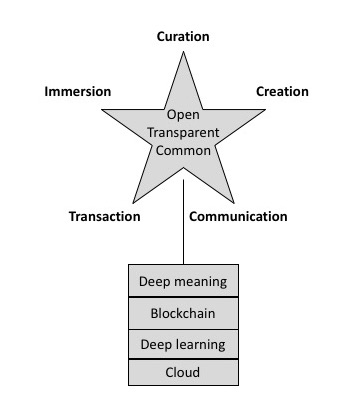
“Du deep learning (de l’apprentissage profond) au deep meaning (à la signification profonde)
Cette nouvelle plateforme publique sera basée sur le web et ses standards ouverts comme http, URL, html, etc. Comme toutes les plateformes actuelles, elle profitera de l'informatique distribuée dans le cloud et utilisera l'apprentissage en profondeur: une intelligence artificielle technologie qui utilise des puces et des algorithmes spécialisés qui imitent à peu près le processus d'apprentissage des neurones. Enfin, pour être complètement à jour, la prochaine plate-forme publique permettra des paiements, des transactions, des contrats et des enregistrements sécurisés en mode blockchain”.
Extraits du Blog de Pierre Levy : https://pierrelevyblog.com/tag/ieml/
Tout bientôt vont arriver sur le marché des nouvelles générations de plateformes de recherche et autres services. C’est imminent. C’est un besoin de société, c’est une nécessité de changement d’échelle d’information. A suivre de près dans les prochains mois.
Sources : Image : Pixabay SplitShire
Illustration : Blog de Pierre Levy
Voir plus d'articles de cet auteur










